CAT4KIT
- Ansprechperson:
Dr. Christof Lorenz (IMK-IFU)
- Projektgruppe:
Dr. Romy Fösig (IMK-AAF), Dr. Sabine Barthlott (IMK-ASF), Dr. Christian Werner (IMK-IFU), Dr. Manuel Schmidberger (IMK-TRO), Dr. Uğur Çayoğlu (SCC), Robert Ulrich (BIB)
- Starttermin:
09/2022
- Endtermin:
08/2024
Publikationen
Hadizadeh, M., Lorenz, C., Barthlott, S., Fösig, R., Loewe, K., Rebmann, C., Ertl, B., Ulrich, R., and Bach, F.: FAIR Environmental Data through a STAC-Driven Inter-Institutional Data Catalog Infrastructure – Status quo of the Cat4KIT-project, EGU General Assembly 2024, Vienna, Austria, 14–19 Apr 2024, EGU24-19155, https://doi.org/10.5194/egusphere-egu24-19155, 2024.
Lorenz, C., Hadizadeh, M., Barthlott, S., Fösig, R., Çayoğlu, U., Ulrich, R., and Bach, F.: CAT4KIT: A cross-institutional data catalog framework for the FAIRification of environmental research data, EGU General Assembly 2023, Vienna, Austria, 24–28 Apr 2023, EGU23-15367, https://doi.org/10.5194/egusphere-egu23-15367, 2023.
Mostafa Hadizadeh, Christof Lorenz, Sabine Barthlott, Romy Fösig, Uğur Çayoğlu, Robert Ulrich, Felix Bach: Cat4KIT: A Cross-institutional Data Catalog Framework for the FAIRification of Environmental Research Data, in Heuveline, Vincent, Bisheh, Nina und Kling, Philipp (Hrsg.): E-Science-Tage 2023: Empower Your Research – Preserve Your Data, Heidelberg: heiBOOKS, 2023, S. 149–160. https://doi.org/10.11588/heibooks.1288.c18072
Beschreibung
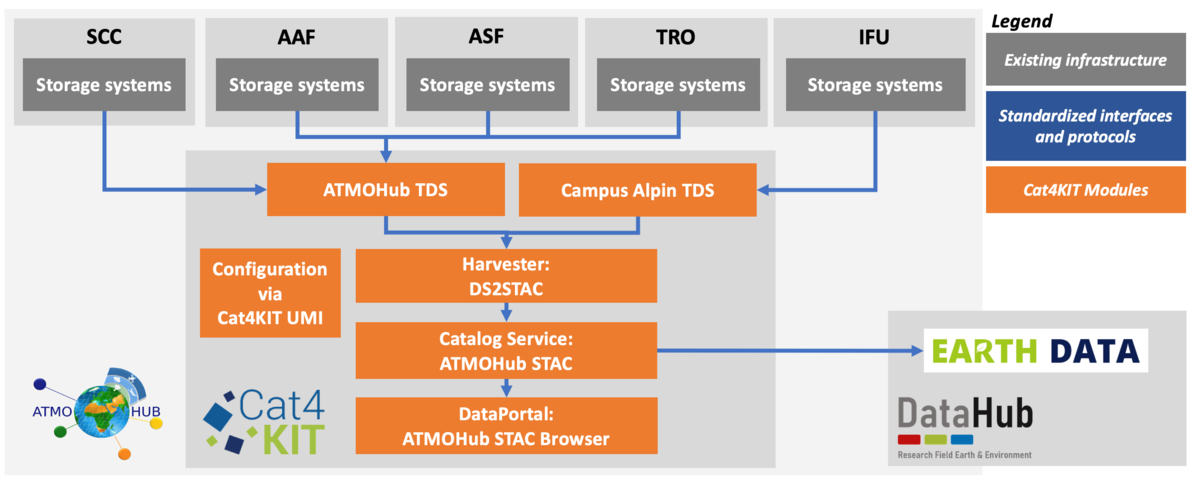
Im Rahmen des Projekts wurde ein einrichtungsübergreifender Katalog für Forschungsdaten in den vier IMK-Instituten des KIT entwickelt, der als zentraler Einstiegspunkt für FAIR- und öffentlich verfügbare Forschungsdaten dient. Er baut auf dem Datenstandard STAC auf und verbindet bestehende Datendienste durch ein modulares, flexibles Softwarepaket. Mit starken Verbindungen zum Helmholtz DataHub und NFDI(4Earth) integriert sich Cat4KIT in übergeordnete Infrastrukturen und unterstützt ein föderiertes Ökosystem für Forschungsdaten am KIT und darüber hinaus.
Ziel war es, einen FDM-Software-Stack zur einrichtungsübergreifenden Bereitstellung, Einbindung, Katalogisierung und Vernetzung von dezentralen Forschungsdaten und Repositorien zu entwickeln. Hierfür wurden Lösungen für vier Datendienste identifiziert, entwickelt, optimiert und schließlich miteinander verknüpft:
- Datenserver: Stellt Daten über standardisierte und programmierbare Schnittstellen bereit und erlaubt so den Zugriff auf und die Einbindung von Remote-Daten.
- Metadaten-Harvester: Durchsucht regelmäßig Kataloge bzw. Repositorien der Datenserver und speichert diese Informationen in einem standardisierten Format ab.
- Katalogdienst: Publiziert Kataloge und ermöglicht so die Verknüpfung mit übergeordneten Dateninfrastrukturen.
- Portaldienst: Frontend bzw. Datenportal zum Durchsuchen und Filtern von Datenkatalogen sowie zur benutzerfreundlichen Darstellung von (Meta-)Daten.
Die einzelnen Dienste wurden dabei als interagierende, aber eigenständige und generalisierte Module umgesetzt. Dadurch wird eine unabhängige Weiterentwicklung und Integration von Teilmodulen sichergestellt, sodass die Dienste möglichst flexibel in verschiedenen Infrastrukturen und Umgebungen am KIT hinaus genutzt werden können.
Um redundante Entwicklungen zu vermeiden und die Einstiegshürde so gering wie möglich zu halten, wurde Cat4KIT auf bereits bestehenden Infrastrukturen (z.B. LSDF, Objektspeicher, GPFS, etc.) und Repositorien (z.B. RADAR4KIT, THREDDS Datenserver, etc.) an den beteiligten Einrichtungen sowie auf verfügbaren Open-Source-Lösungen aufgebaut und vernetzt diese optimal. Besonderer Fokus bei der Entwicklung lag auf der Nutzung von standardisierten Schnittstellen und Protokollen, sodass die am KIT generierten Daten über Cat4KIT in übergeordnete Repositorien wie z.B. der Infrastructure for spatial information in Europe (INSPIRE) der Europäischen Kommission eingebunden werden können.
Durch die generische Entwicklung der Cat4KIT-Module können neue Communities und Repositorien beispielsweise auf den integrierten Katalog- und Portaldienst oder die Bereitstellung von Daten über moderne Schnittstellen wie OPeNDAP zurückgreifen. Dadurch kann das Portfolio an Nutzergruppen erweitert werden und Vorteile eines modernen Forschungsdatenmanagements weitergetragen werden.